들어가며
Karpenter는 노드 스케일링이 필요한 상황에서 1분 내외의 빠른 시간 안에 새로운 노드를 프로비저닝하여, Pending Pod를 빠르게 스케줄링되도록 합니다.
하지만 과연 이것만으로 서비스의 안정성이 더 좋아졌다고 말할 수 있을까요?
물론 프로비저닝 속도는 확실히 빨라졌으나, 안정성이 좋아졌다라고는 말하기에는 살짝 부족합니다.
이유는 실제 서비스 환경은 노드가 프로비저닝되고 새로운 Pod가 스케줄링될 때까지 트래픽들이 기다려주지 않기 때문입니다.
아무리 Karpenter가 빠른 시간안에 프로비저닝 한다고해도, 늘어난 트래픽을 기존 Pod가 처리하지 못하고 에러 응답 및 Pod의 장애를 야기할 수 있고, 비교적 짧은 시간동안에만 폭증한 트래픽(Spike Traffic)의 경우는 기껏 프로비저닝했더니 이미 상황이 종료되었을 수도 있습니다.
즉, 실제 서비스 환경에서는 프로비저닝 속도가 빨라진 것만으로 서비스 안정성을 확보한 것은 아니라는 뜻 입니다.
그럼 서비스 안정성 확보를 위해 Karpenter를 어떻게 활용할 수 있을지 알아보겠습니다.
Over Provisioning
Over Provisioning이란 현재 필요한 수준보다 미리 더 많은 공간을 확보해두는 것으로 아주 간단한 개념입니다.
쿠버네티스의 경우는 Pod가 즉시 스케줄링되어 Running 될 수 있도록 미리 유휴 워커 노드를 준비해두는 방식으로 Over Provisioning 기법을 구현합니다.
워커 노드를 미리 준비해두기 때문에, 비용은 조금 더 사용되겠지만, 갑자기 프로비저닝 상황이 필요할 때는 요긴하게 사용될 수 있습니다.
만약 노드가 Over Provisioning 된 상태라면 아래와 같을 것입니다.
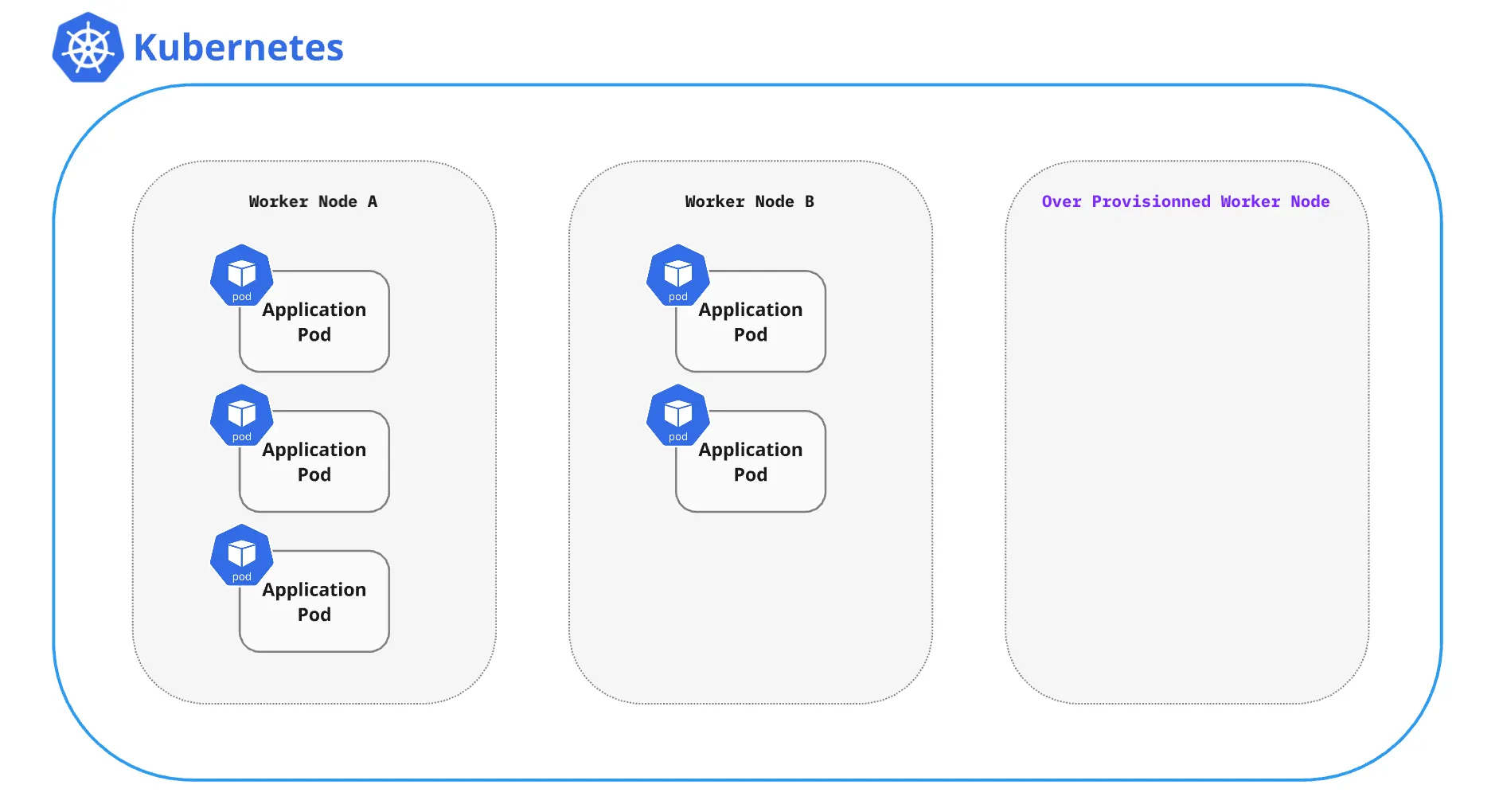
조금 더 상세히 살펴보면, 쿠버네티스에서 트래픽 증가로 Pod의 수가 증가되는 과정은 다음과 같습니다.
•
특정 서비스로의 트래픽 증가
•
해당 서비스 요청을 처리하는 Pod의 CPU/Memory 사용량 증가
•
HPA(Horizontal Pod Autoscaling)에 의해 desiredReplicas 값이 증가되어 추가적인 Pod를 생성
◦
가용 워커 노드가 있는 경우
▪
추가된 Pod가 정상 스케줄링 및 실행되어 늘어난 트래픽에 대응
◦
가용 워커 노드가 없는 경우
▪
새로운 노드를 프로비저닝
▪
생성된 노드에 추가된 Pod를 스케줄링 및 실행하여 늘어난 트래픽에 대응
차이점은 HPA에 의해 추가된 Pod가 즉시 스케줄링될 수 있는지 여부입니다.
만약 가용 워커 노드가 있다면 빠르게 트래픽에 대응이 되겠지만, 그렇지 않은 경우는 어쨌든 새로운 노드를 프로비저닝하는 단계를 거쳐야합니다.
물론 Karpenter 적용을 통해 해당 단계의 시간을 줄였지만, Over Provisining을 사용한다면 아예 생략 가능해집니다.
이렇게 미리 필요한 워커 노드보다 더 많은 노드를 미리 준비해 두는 것을 Over Provisining이라고 합니다.
PriorityClass
Pod는 우선순위를 가질 수 있습니다. 이런 우선순위는 Pod간에 상대적인 중요성을 표시하는데 사용하는데,
Pod를 스케줄링할 수 없는 상태에서 kube-scheduler에게 우선순위가 낮은 Pod를 선점(Preemption, Evict)하여 우선순위가 높은 Pending Pod를 우선 스케줄링하는 역할을 합니다.
Pod의 우선순위가 어디에 필요할까요? 어떤 Pod가 쿠버네티스 클러스터에 중요한지 생각해보면 답을 쉽게 찾을 수 있습니다.
일반적으로 kube-system 네임스페이스에 있는 Pod들이 중요도가 높은 Pod 들입니다.
CoreDNS 및 CNI Pod 또는 로깅을 위한 daemonset등 각각의 노드에 필수로 구동되어야하는 Critical 컴포넌트가 항상 먼저 스케줄링이 되도록 하는 데 사용합니다.

사실 쿠버네티스에는 이미 두 개의 PriorityClass가 기본 사용되고 있습니다.
system-cluster-critical과 system-node-critical는 대부분의 kube-system 네임스페이스의 Pod들에 적용되어 있습니다.
$ kubectl get priorityclasses.scheduling.k8s.io
NAME VALUE GLOBAL-DEFAULT AGE
system-cluster-critical 2000000000 false 531d
system-node-critical 2000001000 false 531d
Bash
복사
이러한 우선순위를 표현하는 오브젝트가 바로 PriorityClass 입니다.
PriorityClass는 non-namespaced 오브젝트로, 정수 값을 통해 Pod에 우선순위를 부여할 수 있도록 합니다.
기본 우선순위 값은 0이며, 10억 이하의 32비트 양/음 정수 값을 사용합니다.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
preemptionPolicy: PreemptLowerPriority|Never
YAML
복사
여기서 특별히 살펴볼 속성은 preemptionPolicy 입니다.
•
preemptionPolicy
◦
PreemptLowerPriority(default): 해당 PriorityClass를 가진 Pod는 낮은 우선순위의 다른 Pod를 축출할 수 있음
◦
Never: 해당 PriorityClass를 가진 Pod는 낮은 우선순위의 Pod보다 먼저 스케줄링되지만, 다른 Pod를 축출할 수 없음
위처럼 정의한 PriorityClass는 PodSpec에 정의하여 Pod에 우선순위를 부여합니다.
PodSpec v1 core
Field | Description |
priorityClassNamestring | If specified, indicates the pod's priority. "system-node-critical" and "system-cluster-critical" are two special keywords which indicate the highest priorities with the former being the highest priority. Any other name must be defined by creating a PriorityClass object with that name. If not specified, the pod priority will be default or zero if there is no default.
값이 지정된 경우 Pod의 우선순위를 나타냅니다. "system-node-critical" 및 "system-cluster-critical"은 가장 높은 우선순위를 나타내는 두 개의 특수 키워드입니다. 다른 이름은 해당 이름으로 PriorityClass 객체를 사전에 생성하여 정의해야 합니다. 지정하지 않으면 포드 우선순위는 기본값이 되고, 기본값이 없으면 0이 됩니다. |
PriorityClass를 Pod에 적용할 때는 priorityClassName에 이름을 명시합니다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
YAML
복사
Karpenter를 통한 Over Provisioning
Karpenter의 Over Provisioning의 핵심은 위에서 설명한 PriorityClass입니다.
PriorityClass는 높은 우선순위를 가진 Pod가 낮은 우선위를 가진 Pod를 축출하고 먼저 스케줄링되게 합니다.
이 스케줄링 원리를 통해 Karpenter에게 미리 노드를 프로비저닝하도록 만들 수 있는데, 아래 그림을 통해 알아보겠습니다.
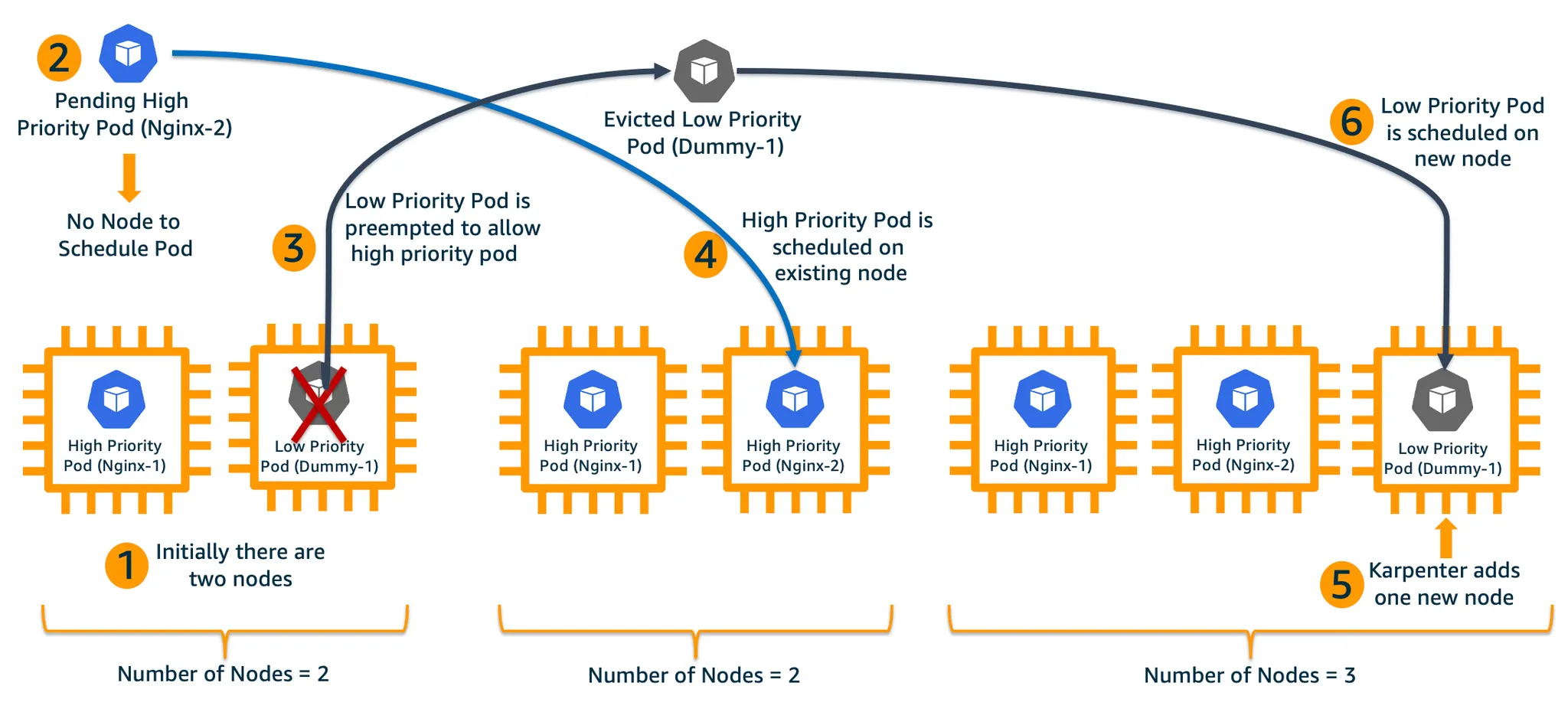
1.
2개의 노드와 High Priority를 가진 Nginx-1 Pod와 Low Priority 를 가진 Dummy-1 Pod가 있으며, 각각의 노드에 스케줄링되어있는 상태Nginx-1 Pod에 대해서는 HPA가 설정되어 있으며 Karpenter가 동작 중
2.
Nginx 서비스의 부하가 증가함에 따라 HPA를 통해 추가 High Priority를 가진 Nginx‑2 Pod가 생성되고, 스케줄링될 노드가 없어 Pending 상태가 됨
3.
Nginx-2 Pod의 우선순위가 더 높고 Pending 상태이므로, kube-scheduler는 낮은 우선순위를 가진 Dummy-1 Pod를 축출하여 Nginx-2 Pod를 위한 공간을 마련
4.
kube-scheduler는 High Priority를 가진 Pod Nginx-2를 스케줄링
5.
Dummy-1 Pod 는 Pending 상태로 전환되고, Karpenter는 이를 감지하여 클러스터에 세번째 노드를 프로비저닝
6.
새로운 노드가 준비되면 kube-scheduler는 Dummy-1를 해당 노드에 스케줄링
Karpenter Over Provisioning Helm chart 구성 & 적용
Karpenter를 사용하는 환경에서 Over Provisioning을 쉽게 적용하기 위해 Helm chart를 구성했습니다.
아래 깃허브를 참고해주세요.
values 파일은 다음과 같이 구성되어있습니다.
# Default values for karpenter-over-provisioning.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
nameOverride: ""
fullnameOverride: ""
replicaCount: 1
image:
name: alpine:3.19
podAnnotations:
sidecar.istio.io/inject: "false"
podLabels: {}
nodeSelector:
nodepool: <nodepool-name>
resources:
limits:
cpu: 6
memory: 4Gi
requests:
cpu: 6
memory: 4Gi
# Priority Class Configuration
priorityClass:
value: -1
YAML
복사
적용 결과
적용 후 np-test-arm64 노드의 상태
$ kubectl get nodes -L nodepool | grep np-apigw-arm64
ip-100-64-224-92.ap-northeast-2.compute.internal Ready <none> 13d v1.27.15-eks-1552ad0 np-test-arm64
ip-100-64-225-209.ap-northeast-2.compute.internal Ready <none> 19d v1.27.12-eks-ae9a62a np-test-arm64
ip-100-64-230-112.ap-northeast-2.compute.internal Ready <none> 12d v1.27.15-eks-1552ad0 np-test-arm64
ip-100-64-233-219.ap-northeast-2.compute.internal Ready <none> 19d v1.27.12-eks-ae9a62a np-test-arm64
ip-100-64-237-69.ap-northeast-2.compute.internal Ready <none> 12d v1.27.15-eks-1552ad0 np-test-arm64
ip-100-64-238-70.ap-northeast-2.compute.internal Ready <none> 12d v1.27.15-eks-1552ad0 np-test-arm64
ip-100-64-240-46.ap-northeast-2.compute.internal Ready <none> 12d v1.27.15-eks-1552ad0 np-test-arm64
ip-100-64-241-249.ap-northeast-2.compute.internal Ready <none> 12d v1.27.15-eks-1552ad0 np-test-arm64
ip-100-64-244-240.ap-northeast-2.compute.internal Ready <none> 12d v1.27.15-eks-1552ad0 np-test-arm64
ip-100-64-245-83.ap-northeast-2.compute.internal Ready <none> 19d v1.27.12-eks-ae9a62a np-test-arm64
ip-100-64-249-107.ap-northeast-2.compute.internal Ready <none> 18d v1.27.12-eks-ae9a62a np-test-arm64
ip-100-64-252-60.ap-northeast-2.compute.internal Ready <none> 12d v1.27.15-eks-1552ad0 np-test-arm64
ip-100-64-254-160.ap-northeast-2.compute.internal Ready <none> 19d v1.27.12-eks-ae9a62a np-test-arm64
ip-100-64-255-233.ap-northeast-2.compute.internal Ready <none> 115s v1.27.15-eks-1552ad0 np-test-arm64
YAML
복사
위 노드 리스트 중 가장 최근에 생성된 ip-100-64-255-233.ap-northeast-2.compute.internal 는 dummy Pod가 만들어낸 Over Provisining Node 입니다.
실제로 해당 노드에 스케줄링된 Pod를 살펴보면 다음과 같습니다.
$ kubectl get pods -A --field-selector=spec.nodeName=ip-100-64-255-233.ap-northeast-2.compute.internal
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system aws-node-qgcsg 1/1 Running 0 12m
kube-system ebs-csi-node-kph5d 3/3 Running 0 12m
kube-system efs-csi-node-vklx8 3/3 Running 0 12m
kube-system kube-proxy-wxkjn 1/1 Running 0 12m
kube-system node-local-dns-stxjr 1/1 Running 0 12m
ns-cluster fluent-bit-xblvd 1/1 Running 0 12m
ns-cluster kic-np-test-arm64-over-provisioning-598fc4df67-v2z6l 1/1 Running 0 12m
ns-mgmt datadog-6l92q 4/4 Running 0 12m
ns-mgmt falco-5xlt7 2/2 Running 0 12m
ns-mgmt prometheus-prometheus-node-exporter-7pmth 1/1 Running 0 12m
YAML
복사
kube-system 네임스페이스에서 실행중인 각종 시스템 관련 Pod 들과 datadog, prometheus등 daemonset으로 인해 생겨난 Pod 들 외에는 없는 것을 볼 수 있습니다.
특히 kic-np-test-arm64-over-provisioning-598fc4df67-v2z6l 라는 이름의 dummy Pod만 스케줄링되어 새로운 Pod를 점유하고 있는 것을 확인할 수 있습니다.
마치며
지난 포스팅에서 CA와 Karpenter에 대해 알아보고, 이번 포스팅에서는 Karpenter를 통한 Over Provisioning 기법을 살펴봤습니다.
실제로 제가 관리하는 EKS에서 운영중인 서비스는 가전 관련된 서비스로 계절/시간에 따라 트래픽 차이가 명확히 드러납니다.
트래픽이 갑자기 늘어날 때, 노드 프로비저닝 시간을 단축시켜 빠르게 트래픽을 대응하는데 실질적으로 도움이 되고 있습니다.
물론 평상시에도 1~2개의 노드를 더 유지해야하기 때문에 비용적으로 부담이 될 수는 있지만, 안정적인 서비스를 위해서 이정도는 괜찮지 않을까요?
