
들어가며
쿠버네티스에는 기본적으로 Pod의 CPU, Memory 사용량을 기반으로 Replica 수를 동적으로 조정할 수 있도록 HPA(Horizontal Pod Autoscaler)를 지원합니다.
그러나 실제 운영 환경에서는 오토스케일링의 기준을 다양하게 가져가야하는 경우나, 조금 더 디테일하게 Pod 수를 조절하고 싶은 경우가 빈번하게 발생합니다.
이를 위한 KEDA(Kuberneters Event-Driven Autoscaler)에 대해서 알아보고 실습해보겠습니다.
KEDA

KEDA는 Kubernetes Event-driven Autoscaling의 약자로, Microsoft와 Red Hat이 공동으로 개발한 오픈소스 프로젝트입니다.
KEDA는 Kubernetes의 기본 오토스케일링 기능을 확장하여, 다양한 이벤트 소스로부터의 메트릭을 기반으로 워크로드를 스케일링할 수 있게 만듭니다.
기존에 쿠버네티스 HPA는 CPU, Memory를 기반으로 Pod 수를 조정하는데, Pod 수를 조정하는 기준을 CPU, Memory 뿐만아니라 다양한 기준을 사용하여 조정할 수 있도록 도와주는 도구라고 이해하시면 됩니다.
KEDA Architecture
아래는 KEDA의 아키텍처 디자인으로써 Kubernetes HPA와 어떻게 동작하는지, 또한 외부 이벤트 소스(External trigger source)와 함께 작동하는 방식을 설명합니다.
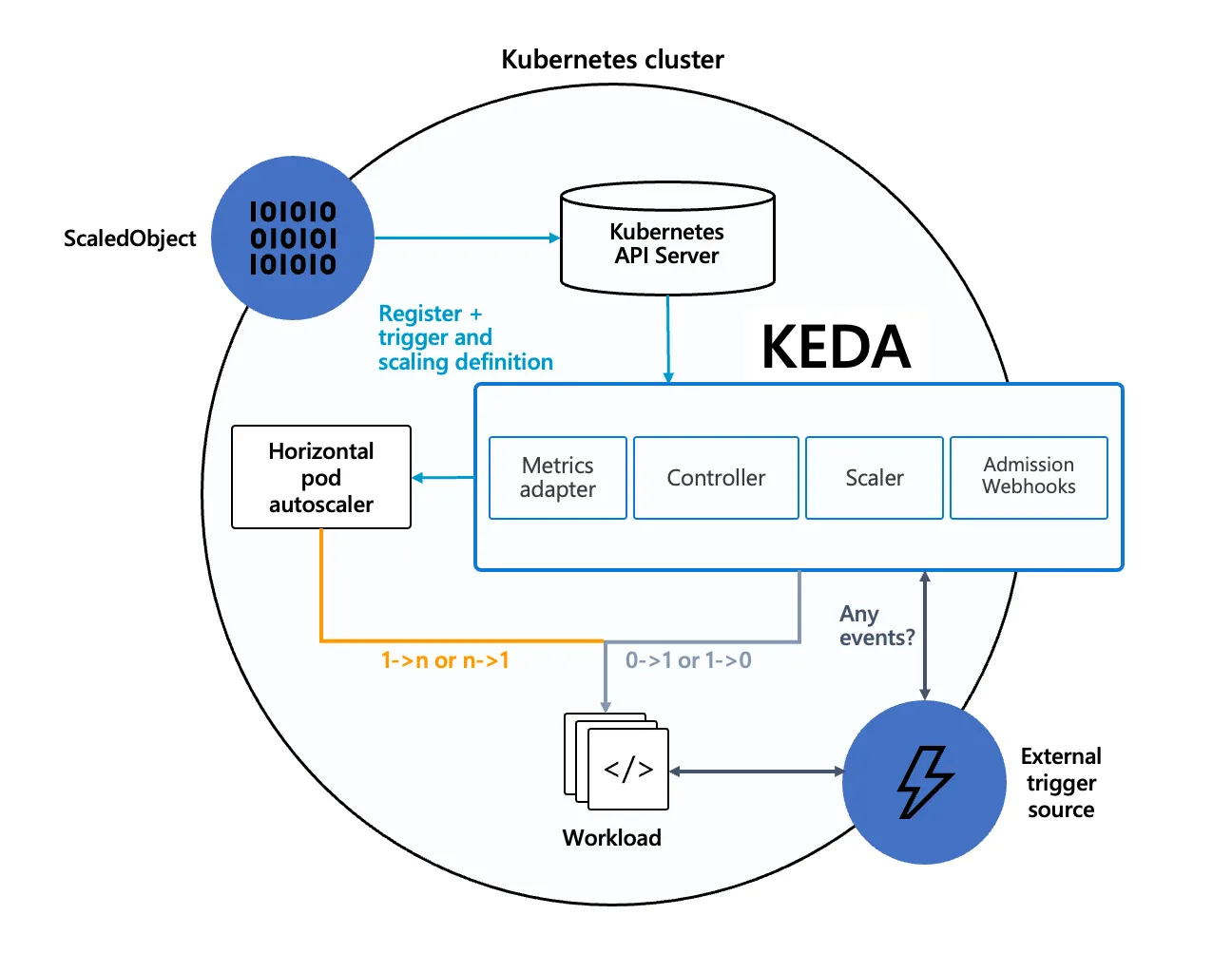
여기서 눈여겨볼 것은 KEDA는 기존 Kubernetes 클러스터의 HPA를 교체하는 방식이 아닌, HPA와 함께 동작하며 오토스케일링 기능을 확장한다는 점입니다.
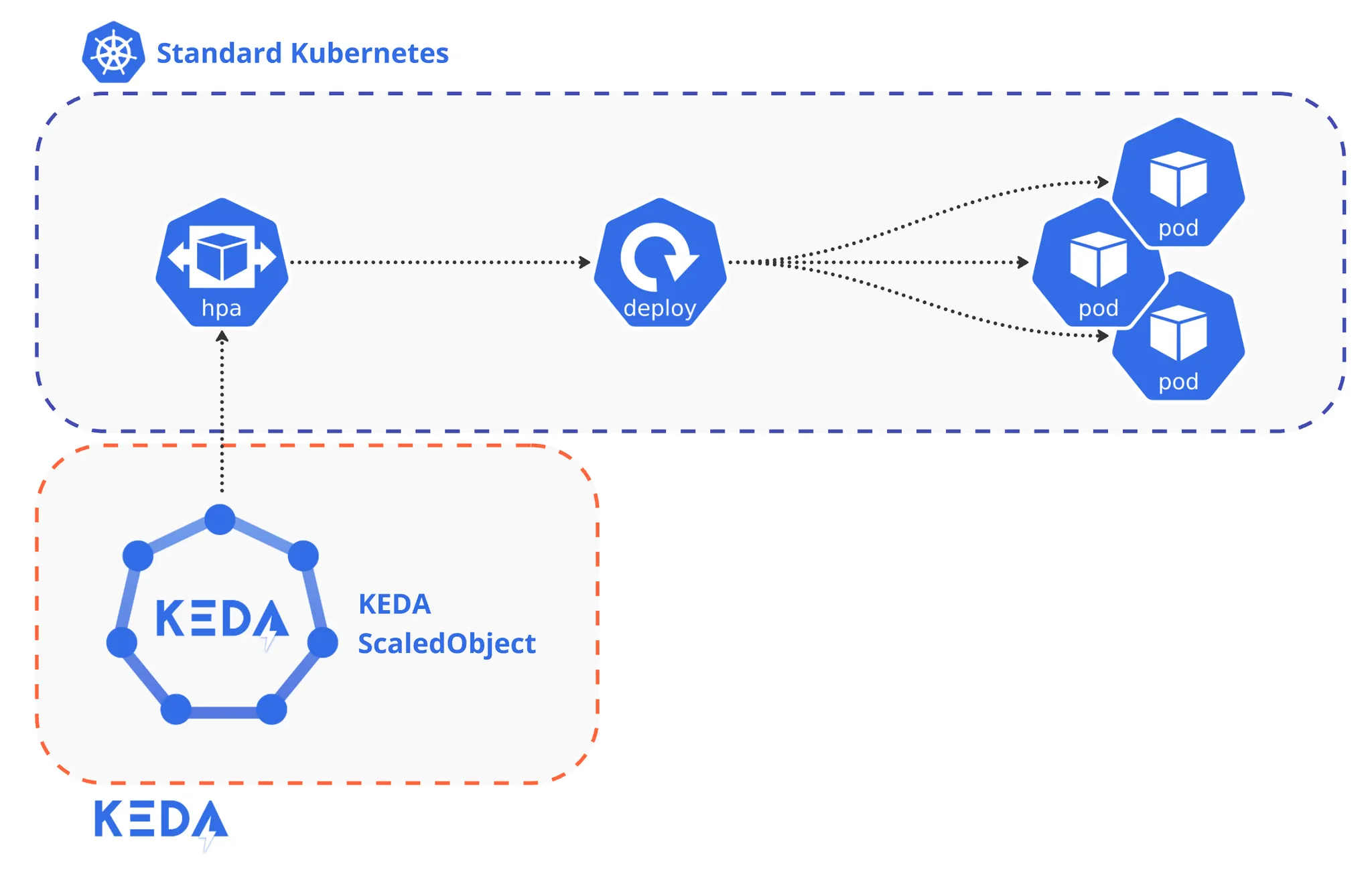
이는 클러스터 관리자입장에서 굉장한 이점으로 작용합니다. KEDA를 사용하기 위해 기존 클러스터의 일부를 교체/변경하는 것이 아니기 때문입니다.
또한 마이그레이션 과정이 특별히 없다고 봐도 됩니다. KEDA를 설치하더라도 기존 HPA는 그대로 동작하니까요.
덕분에 당장 모든 워크로드들이 스케일링 동작을 위해 KEDA의 scaledObject로 변경하지 않아도됩니다.
물론 KEDA를 통해 스케일링하려면 기존 HPA는 삭제해야하지만, 이게 큰 어려움은 아닙니다.
기본 노드 오토스케일러인 Cluster Autoscaler 에서 Karpenter로 마이그레이션 하는 것과는 그 무게감이 완전히 다릅니다.
KEDA의 장점
•
더 다양하고 유연한 스케일링
◦
CPU/메모리 외의 다양한 메트릭 기반 스케일링 가능
◦
0개 스케일링 지원
◦
다양한 워크로드 타입 지원 (Deployment, StatefulSet, Job 등)

•
쉬운 설치/적용
◦
기존 Kubernetes HPA와 함께 동작하며, 클러스터에 영향도가 적음
•
비용 효율성
◦
실제 사용에 따른 정확한 스케일링으로 리소스 낭비 감소
KEDA CustomResource
ScaledObject
ScaledObject KEDA의 핵심 커스텀 리소스로, 스케일링 대상과 조건을 정의합니다.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-scaledobject
spec:
scaleTargetRef: # 스케일링할 대상 워크로드
apiVersion: apps/v1
kind: Deployment
name: consumer-deployment
pollingInterval: 30 # 메트릭 수집 주기 (초)
cooldownPeriod: 300 # 스케일 다운 전 대기 시간
minReplicaCount: 0 # 최소 레플리카 수
maxReplicaCount: 100 # 최대 레플리카 수
triggers: # 스케일링 트리거 정의
- type: rabbitmq
metadata:
queueName: myqueue
host: rabbitmq.default
queueLength: "50" # 큐 길이가 50 이상이면 스케일 아웃
YAML
복사
•
scaleTargetRef: 스케일링할 대상 워크로드를 지정
•
pollingInterval: 메트릭 수집 주기 설정
•
cooldownPeriod: 스케일 다운 전 대기 시간
•
minReplicaCount: 최소 레플리카 수 (0으로 설정 가능)
•
maxReplicaCount: 최대 레플리카 수
•
triggers: 스케일링 트리거 조건 정의 (여러 트리거 동시 설정 가능)
ScaledJob
Kubernetes Job을 이벤트 기반으로 스케일링할 때 사용됩니다.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: prometheus-scaledjob
spec:
jobTargetRef: # 실행할 Job 템플릿
template:
spec:
containers:
- name: processor
image: myregistry/processor:v1
pollingInterval: 30 # 메트릭 수집 주기
successfulJobsHistoryLimit: 5 # 성공한 Job 히스토리 보존 수
failedJobsHistoryLimit: 5 # 실패한 Job 히스토리 보존 수
maxReplicaCount: 100 # 동시 실행 가능한 최대 Job 수
triggers: # 스케일링 트리거 정의
- type: prometheus
metadata:
serverAddress: http://prometheus.monitoring
query: sum(rate(http_requests_total{code=~"^5.*"}[2m]))
threshold: "100"
YAML
복사
•
jobTargetRef: 실행할 Job의 템플릿 정의
•
pollingInterval: 메트릭 수집 주기
•
successfulJobsHistoryLimit: 성공한 Job의 히스토리 보존 수
•
failedJobsHistoryLimit: 실패한 Job의 히스토리 보존 수
•
maxReplicaCount: 동시 실행 가능한 최대 Job 수
•
triggers: Job 생성 트리거 조건 정의
TriggerAuthentication
TriggerAuthentication 는 외부 메트릭 소스에 접근하기 위한 인증 정보를 관리합니다.
시크릿, 환경 변수 등 다양한 방식의 인증을 지원합니다.
ClusterTriggerAuthentication
TriggerAuthentication 의 클러스터 범위 리소스입니다.
클러스터 전체에서 재사용 가능한 인증 설정을 정의합니다.
ScaledObject를 통한 스케일링 테스트
Cron을 통한 특정 시간 스케일링
일반적으로 HPA를 사용한다면 트래픽 유입에 따라 높아지는 Pod의 CPU/Memory 사용량을 기반으로 Pod를 오토스케일링하는 방법을 사용합니다.
하지만 이 방법은 트래픽이 이미 높아진 상황에서의 스케일링이라 반응속도가 늦기 마련입니다.
어떤 서비스를 운영하다보면 특정 시간대에 트래픽이 집중되는 경향을 보이는 것이 일반적입니다.
이를 대비하기 위해 특정 시간대에 미리 Pod를 스케일 아웃하는 방법을 한 번 알아보겠습니다.
오후 17:40~18:00 동안 트래픽이 대량으로 유입되는 서비스가 있다고 가정하겠습니다.
해당 시간에 Pod 수를 미리 늘려 놓으면 대량 트래픽을 훨씬 잘 소화할 수 있을 것 입니다.
아래 scaledObject는 nginx-keda-test 라는 Deployment의 Pod 갯수를 기본 2개에서, 오후 17:40~18:00 동안 최소 5개가 유지될 수 있도록 합니다.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: nginx-cron
namespace: keda-test
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-keda-test # 타겟 디플로이먼트 이름
minReplicaCount: 2 # 기본 최소 레플리카 수
maxReplicaCount: 20 # 최대 레플리카 수
fallback:
failureThreshold: 3
replicas: 2
triggers:
# 기본 트리거 (CPU 사용률)
- type: cpu
metricType: Utilization
metadata:
value: "50"
# 매 정각마다 5개의 레플리카를 보장하는 Cron trigger
- type: cron
metadata:
timezone: Asia/Seoul # 타임존 설정
start: 40 17 * * * # 17:40 시작
end: 00 18 * * * # 18:00 종료
desiredReplicas: "5" # 원하는 레플리카 수
YAML
복사
먼저 스케일링 대상인 Deployment를 생성하고, 위에 작성해둔 scaledObject를 생성합니다.
사용한 Deployment의 yaml은 클릭하여 확인하세요.
scaledObject를 생성하니 KEDA의 scaledObject 뿐만아니라, hpa까지 함께 생성된 것을 확인할 수 있습니다.
kubeadm ~/workspace/seowoo.gong/keda $ kubectl get pods,hpa,scaledobject -n keda-test
NAME READY STATUS RESTARTS AGE
pod/nginx-keda-test-695dbf7d87-fcf2p 1/1 Running 0 25s
pod/nginx-keda-test-695dbf7d87-n89gc 1/1 Running 0 25s
kubeadm ~/workspace/seowoo.gong/keda $ kubectl apply -f scaledobject-cron-1.yaml
scaledobject.keda.sh/nginx-cron created
Bash
복사
오후 5시40분, scaledObject의 ACTIVE: True 가 되며, Pod가 5개로 증설된 것을 확인할 수 있습니다.
kubeadm ~/workspace/seowoo.gong/keda $ kubectl get pods,hpa,scaledobject -n keda-test
NAME READY STATUS RESTARTS AGE
pod/nginx-keda-test-695dbf7d87-fcf2p 1/1 Running 0 2m12s
pod/nginx-keda-test-695dbf7d87-n89gc 1/1 Running 0 2m12s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-nginx-cron Deployment/nginx-keda-test 500m/1 (avg), 0%/50% 2 20 2 100s
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX READY ACTIVE FALLBACK PAUSED TRIGGERS AUTHENTICATIONS AGE
scaledobject.keda.sh/nginx-cron apps/v1.Deployment nginx-keda-test 2 20 True False False Unknown 100s
Bash
복사
오후 6시, scaledObject의 ACTIVE: False 로 변경되며, 잠시 후 원래 Pod 갯수인 2개로 돌아오게 됩니다.
kubeadm ~/workspace/seowoo.gong/keda $ kubectl get pods,hpa,scaledobject -n keda-test
NAME READY STATUS RESTARTS AGE
pod/nginx-keda-test-695dbf7d87-2jjxm 1/1 Running 0 41s
pod/nginx-keda-test-695dbf7d87-7q6n9 1/1 Running 0 26s
pod/nginx-keda-test-695dbf7d87-8rbgt 1/1 Running 0 41s
pod/nginx-keda-test-695dbf7d87-fcf2p 1/1 Running 0 6m58s
pod/nginx-keda-test-695dbf7d87-n89gc 1/1 Running 0 6m58s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-nginx-cron Deployment/nginx-keda-test 1/1 (avg), 2%/50% 2 20 5 6m26s
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX READY ACTIVE FALLBACK PAUSED TRIGGERS AUTHENTICATIONS AGE
scaledobject.keda.sh/nginx-cron apps/v1.Deployment nginx-keda-test 2 20 True True False Unknown 6m26s
Bash
복사
kubeadm ~/workspace/seowoo.gong/keda $ kubectl get pods,hpa,scaledobject -n keda-test
NAME READY STATUS RESTARTS AGE
pod/nginx-keda-test-695dbf7d87-2jjxm 1/1 Running 0 21m
pod/nginx-keda-test-695dbf7d87-7q6n9 1/1 Running 0 20m
pod/nginx-keda-test-695dbf7d87-8rbgt 1/1 Running 0 21m
pod/nginx-keda-test-695dbf7d87-fcf2p 1/1 Running 0 27m
pod/nginx-keda-test-695dbf7d87-n89gc 1/1 Running 0 27m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-nginx-cron Deployment/nginx-keda-test 200m/1 (avg), 0%/50% 2 20 5 26m
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX READY ACTIVE FALLBACK PAUSED TRIGGERS AUTHENTICATIONS AGE
scaledobject.keda.sh/nginx-cron apps/v1.Deployment nginx-keda-test 2 20 True False False Unknown 26m
-------------- 잠시 후 --------------
kubeadm ~/workspace/seowoo.gong/keda $ kubectl get pods,hpa,scaledobject -n keda-test
NAME READY STATUS RESTARTS AGE
pod/nginx-keda-test-695dbf7d87-2jjxm 1/1 Running 0 24m
pod/nginx-keda-test-695dbf7d87-7q6n9 1/1 Running 0 24m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-nginx-cron Deployment/nginx-keda-test 200m/1 (avg), 0%/50% 2 20 5 30m
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX READY ACTIVE FALLBACK PAUSED TRIGGERS AUTHENTICATIONS AGE
scaledobject.keda.sh/nginx-cron apps/v1.Deployment nginx-keda-test 2 20 True False False Unknown 30m
Bash
복사
마치며
KEDA는 쿠버네티스에서 다양한 방법과 조건으로 Pod를 오토스케일링할 수 있도록 만들어준다는 점에서 아주 유용합니다. (실제로 HPA가 너무 단순해서 대응하기 어려운 경우가 많습니다.)
개인적으로 가장 맘에드는 점은 다양한 스케일러가 있다는 것보다도 기존 오토스케일링 리소스인 HPA를 대체하는 것이 아닌, HPA와 함께 동작하며 그 기능을 확장하는 개념이라는 부분입니다.
기존 클러스터의 구조를 크게 변경하지 않으면서 다양한 방법으로 Pod를 오토스케일링 할 수 있도록 도와주는 KEDA를 어느정도 쿠버네티스에 익숙해지신 분들이라면 한 번 적용해보는 것도 좋을 것 같습니다.