조금 늦었지만, 최근 제가 회사에서 운용하고 있는 7개의 AWS EKS 클러스터의 AutoScaler를 Karpenter로 모두 마이그레이션을 마쳤습니다.
이를 기념하기 위해(?) Karpenter에 관한 이야기를 조금씩 나눠서 포스팅하려고 합니다.
이번 포스팅에서는 그 첫번째로 Karpenter에 대한 개요와 일반적으로 노드 확장을 위해 자주 사용하는 Cluster Autoscaler 와 비교를 통해 무엇이 좋은지 확인해보겠습니다.
TL;DR
•
쿠버네티스 및 EKS는 노드를 오토스케일링하는데 기본 도구로 Cluster Autoscaler를 사용
•
Cluster Autoscaler는 노드의 프로비저닝 속도가 상대적으로 느리며, 이로 인해 Pod의 오토스케일링에 빠르게 대응하지 못하는 경우가 빈번함
•
Karpenter는 노드 프로비저닝 속도가 빠르고, 여러가지 노드 타입/사이즈를 사용하도록 설정할 수 있으며, 다양한 기능으로 비용 효율성을 높이는 설정이 가능
Karpenter 마이그레이션 계기
Karpenter에 대해 본격적으로 설명하기 전에, 왜 Karpenter로 오토스케일러를 마이그레이션 했는지 이야기를 해보려고 합니다.
다른 포스팅에서 언급한지 있는지 모르겠지만 저는 현재 LG전자에서 플랫폼 엔지니어링을 하고 있습니다.
아무래도 가전 제품 관련 서비스가 주를 이루다보니 받는 트래픽이 우리의 삶과 관련된 몇가지 재밌는 특징을 갖고 있습니다.
•
가전 제품에 대한 서비스다보니 계절에 따라 트래픽의 차이가 큽니다.
◦
여름에 다들 에어컨을 사용하기 때문에, 여기서 발생하는 요청과 데이터가 급증합니다.
•
또한 특정 시간대, 이벤트에 대한 트래픽 차이가 큽니다.
◦
예를 들면, 주말에 TV 사용량이 많아진다거나, 저녁에 축구 국가대표 경기가 있는 등…
위처럼 계절 및 특정 시간대에 트래픽이 몇 배로 증가하는 것을 대비하기 위해 Pod를 항시 띄워두는 것은 여러모로 비효율적입니다.
그러나 HPA를 통해 Pod의 갯수가 조절되더라도, Pod가 스케줄링될 노드의 프로비저닝이 늦어지면 갑자기 늘어난 트래픽에 대응이 늦어지는건 마찬가지입니다.
특히 Spike Traffic의 경우 대부분 5분 내에 해소되는 경우가 많은데(제 경우입니다), 애써 노드 새로 만들어지고 Pod 새로 띄우고나면 이미 상황이 다 끝난 경우가 허다했습니다.
그래서 좀 더 트래픽이 몰리는 상황에 잘 대응하기 위해 노드 역시 빠르게 프로비저닝이 되어야 함을 느꼈고, CA보다 노드 프로비저닝 속도가 빠른 Karpenter로 마이그레이션을 결정하게 되었습니다.
Cluster Autoscaler vs Karpenter
Cluster Autoscaler(CA or CAS)
Cluster Autoscaler는 쿠버네티스 초창기 오픈소스로, Kubernetes 클러스터의 크기를 자동으로 조정하는 도구입니다.
초창기부터 사용되어 기본적으로 여러 클라우드 벤더와 호환이 가능한 장점이 있습니다.
다만, 호환성을 높이기 위해 NodeGroup이라는 추상화 레이어가 존재하며, Kubernetes-Native 형태로 개발되지 않았습니다.

Kubernetes-Native
Kubernetes-Native란 어떤 애플리케이션이 쿠버네티스에 정의된 리소스들과 상호 작용하여 동작하며 배포, 구성, 관리되는 방식 전반을 말합니다.
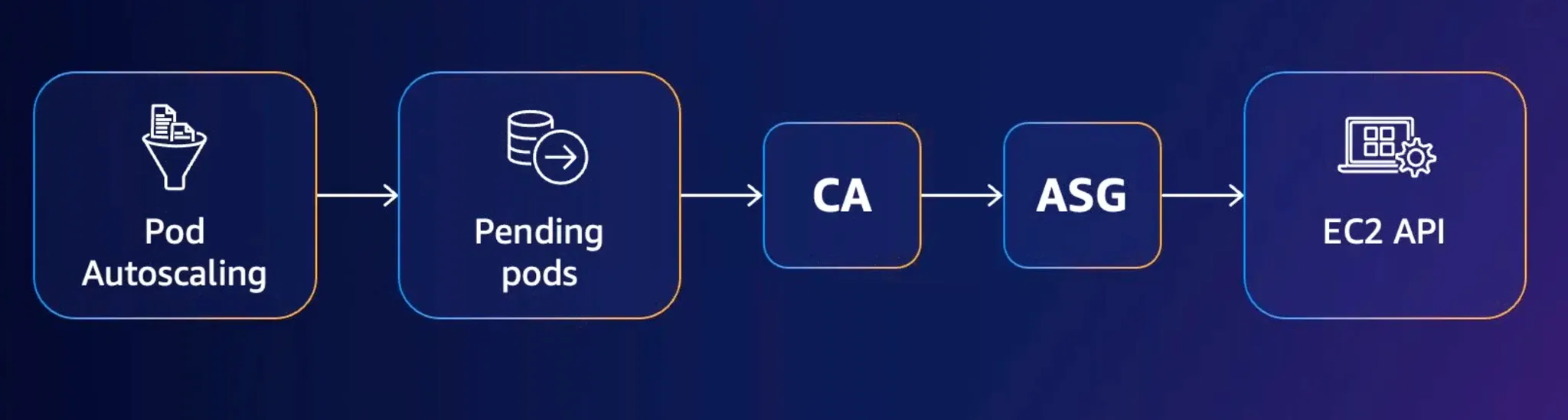
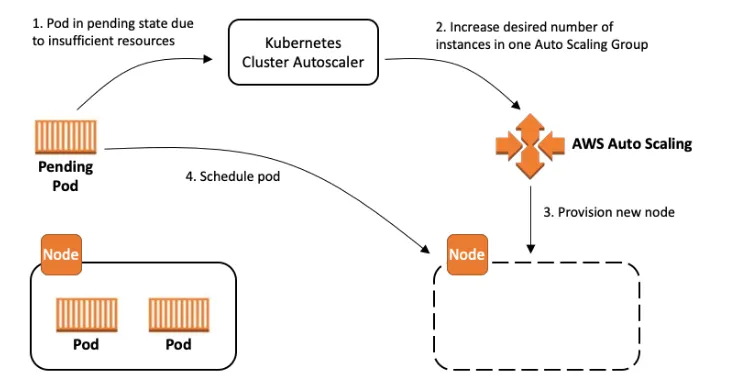
Cluster Autoscaler의 동작 방식은 아래와 같습니다.
•
노드에 스케줄링 되지 못한 Pending Pod가 발생
•
노드 scale up/down이 필요한지 Cluster Autoscaler가 주기적으로 검사 (Polling, default 10초)
scan-interval | How often cluster is reevaluated for scale up or down | 10 seconds |
•
Cluster Autoscaler가 AWS Auto Scaling Group를 호출
•
ASG가 EC2 API를 호출하여 새로운 노드를 프로비저닝
좀 더 디테일한 동작은 아래를 참고해주세요.
CA의 단점을 꼽자면 다음과 같이 나열할 수 있습니다.
•
새로운 노드를 프로비저닝하기까지 ASG를 거쳐야하며, 노드 scale up/down을 Polling 방식 (Not Kubernetes-Native)으로 판단하기에 상대적으로 노드 프로비저닝 트리거가 느립니다. (최대 10초 소요)
•
트리거 후에도 프로비저닝을 AWS Auto Scaling Group를 통해 수행하기 때문에 상대적으로 느립니다.
•
각 노드 그룹은 하나의 노드 타입과 크기를 설정할 수 있어서 리소스 낭비 가능성이 있습니다.
Karpenter
Karpenter는 AWS가 개발한 오픈소스이며 Kubernetes-Native로 동작합니다.
Karpenter의 특징은 다음과 같습니다.
•
추상화 레이어를 제거
•
Pending Pod를 감지하여 노드 프로비저닝
•
Pending Pod가 구동될 수 있는 최적화된 노드를 선택하여 프로비저닝
•
배포된 Pod들에 최적화된 노드로 자동으로 크기 조정 (Consolidation)을 통해 비용 효율성을 높임
→ 추후에 언급하겠지만 Consolidation은 Pod가 새로 스케줄링되므로 안정적인 서비스 운영에서는 권장되지 않습니다.
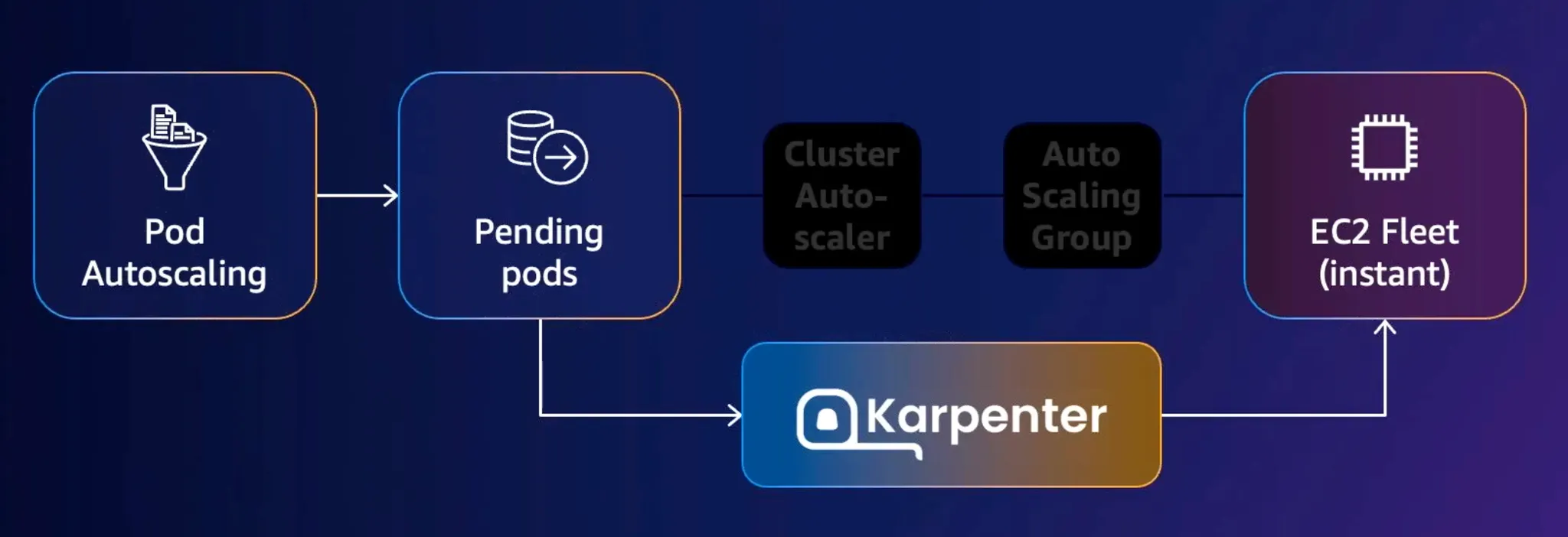
Karpenter의 동작 방식은 다음과 같습니다.
•
노드에 스케줄링 되지 못한 Pending Pod가 발생
•
Pod의 Status를 모니터링하다가 Pending Pod가 발생하면 Karpenter가 실시간으로 감지 (Kubernetes-Native)
•
Karpenter는 EC2 Fleet API를 direct로 호출하여 노드 프로비저닝
CA 대비 Karpenter의 장점은 다음과 같습니다.
•
Karpenter는 EC2 Fleet API를 직접 호출하여 프로비저닝의 중간 과정을 제거합니다.
•
Pending Pod를 모니터링하고 반응하기 때문에 빠르게 프로비저닝이 트리거됩니다.
•
Karpenter에게 CRD를 통해 다양한 노드 타입, 크기 후보 군을 설정할 수 있으며, 최적의 노드를 자동으로 선택하여 프로비저닝합니다.
프로비저닝 시간 비교
Cluster Autoscaler
Documentation에 의하면 Cloud Provider에 따라 프로비저닝 시간은 다르지만, GCE의 경우 노드를 새로 생성하여 Pod를 스케줄링하는데 보통 3~4분이 걸린다고 합니다.
지금까지 제가 EKS에서 Cluster Autoscaler를 사용한 경험상 2분 내로는 노드가 프로비저닝 되었습니다.
다음은 EKS + Cluster Autoscaler로 노드 프로비저닝 테스트를 진행한 내용입니다.

•
Pending 상태 Pod 발생

•
Pending Pod 발생 시간 기준으로 61초 후 NotReady 상태 노드 확인

•
30초 후 노드 Ready

•
94초 후 Pod가 스케줄링되어 Running 상태로 전환
여러번 테스트해야 정확해지겠지만, 약 1~2분 내로 Cluster Autoscaler도 노드를 프로비저닝합니다.
옛날에는 3분넘게 걸렸다는데, 그동안 많이 최적화가 된 것으로 보입니다.
Karpenter
Karpenter는 대략적인 프로비저닝 시간을 확인할 수는 없지만, 대체로 1분 안으로 프로비저닝된다는 사용기를 많이 확인할 수 있습니다.
다음은 EKS + Karpenter로 노드 프로비저닝 테스트를 진행한 내용입니다.

•
Pending 상태 Pod 발생

•
Pending Pod 발생 시간 기준으로 22초 후 NotReady 상태 노드 확인

•
23초 후 노드 Ready

•
46초 후 Pod가 스케줄링되어 Running 상태로 전환
생성된 Node가 NotReady → Ready 상태로 전환되는데는 거의 비슷한 시간이 소요되는데, 확실히 노드가 쿠버네티스 클러스터에 인식되는 시간이 74초와 27초로 상당히 줄어든 것을 볼 수 있습니다.
그 이유는 위에서 설명했던 구조와 Pending Pod 감지하는 방식의 차이로 설명이 가능합니다.
•
Pending Pod를 Polling 으로 확인하는지 vs Pod status로 즉시 확인하는지
•
ASG를 통해 EC2 API를 호출하는지 vs 직접 EC2 API를 호출하는지
위 두가지의 이유 모두 새로운 노드를 생성하기까지의 시간에 영향을 주기 때문에 많은 시간 단축을 확인할 수 있습니다.
요약
Cluster Autoscaler | Karpenter | 증감 | |
노드 Provisioning & Ready까지의 시간 | 61초 | 22초 | 약 63.9% 감소 |
Pod Running까지의 시간 | 94초 | 46초 | 약 51% 감소 |
마치며
이번 포스팅에서는 Cluster Autoscaler와 Karpenter에 대해서 알아보고, 테스트를 통해 Karpenter가 얼마나 빠르게 새로운 노드를 프로비저닝하는지 확인했습니다.
사실 Karpenter는 아직도 v0.37 이 최신버전이고, 작년까지만해도 이슈 리포트도 잦고 불안정하다는 피드백이 많아서 마이그레이션을 하지 않고 있다가, 최근에 많이 안정화되었다는 의견이 많아져서 7개 EKS 클러스터를 모두 Karpenter로 전환하였습니다.
그 결과로 무엇보다도 전반적인 노드 프로비저닝 시간이 절반정도로 줄어든 점이 가장 고무적입니다.
물론 비용효율성도 Karpenter의 큰 장점이며, 이를 위해 NodePool 구성 및 Spot Instance 사용을 설정하면 비용 측면으로도 많은 개선이 될 것이라 기대하고 있습니다.
다음 포스팅에서는 Karpenter를 통한 Over Provisioning을 적용한 내용을 소개하겠습니다.