

들어가며
쿠버네티스에 애플리케이션을 배포할 때, 안정적인 서비스 제공을 위해 Pod의 replica를 1개가 아닌 2개 이상으로 설정하는 것이 일반적입니다.
이렇게 구성하는 이유는 하나의 Pod에 어떤 장애가 발생하더라도, 다른 Pod가 정상 동작하기 때문에 안정적인 서비스 제공이 가능하기 때문입니다.
만약 모든 Pod가 동일한 워커 노드에 스케줄되어 있는 경우라면 어떻게 될까요? 그림으로 한 번 살펴보겠습니다.
아래 그림처럼 Pod A는 Node 1에 모두 스케줄되어있습니다. 이 때 Node 1에 장애가 생긴다면, 다른 워커 노드에는 Pod A replica가 없기 때문에 서비스 A는 정상 동작을 할 수 없게됩니다.
반면에 Node 1 , Node 2에 분산되어있던 Pod B, Pod C 서비스는 Node 1에 장애가 발생하더라도 Node 2에서 계속 서비스됩니다.
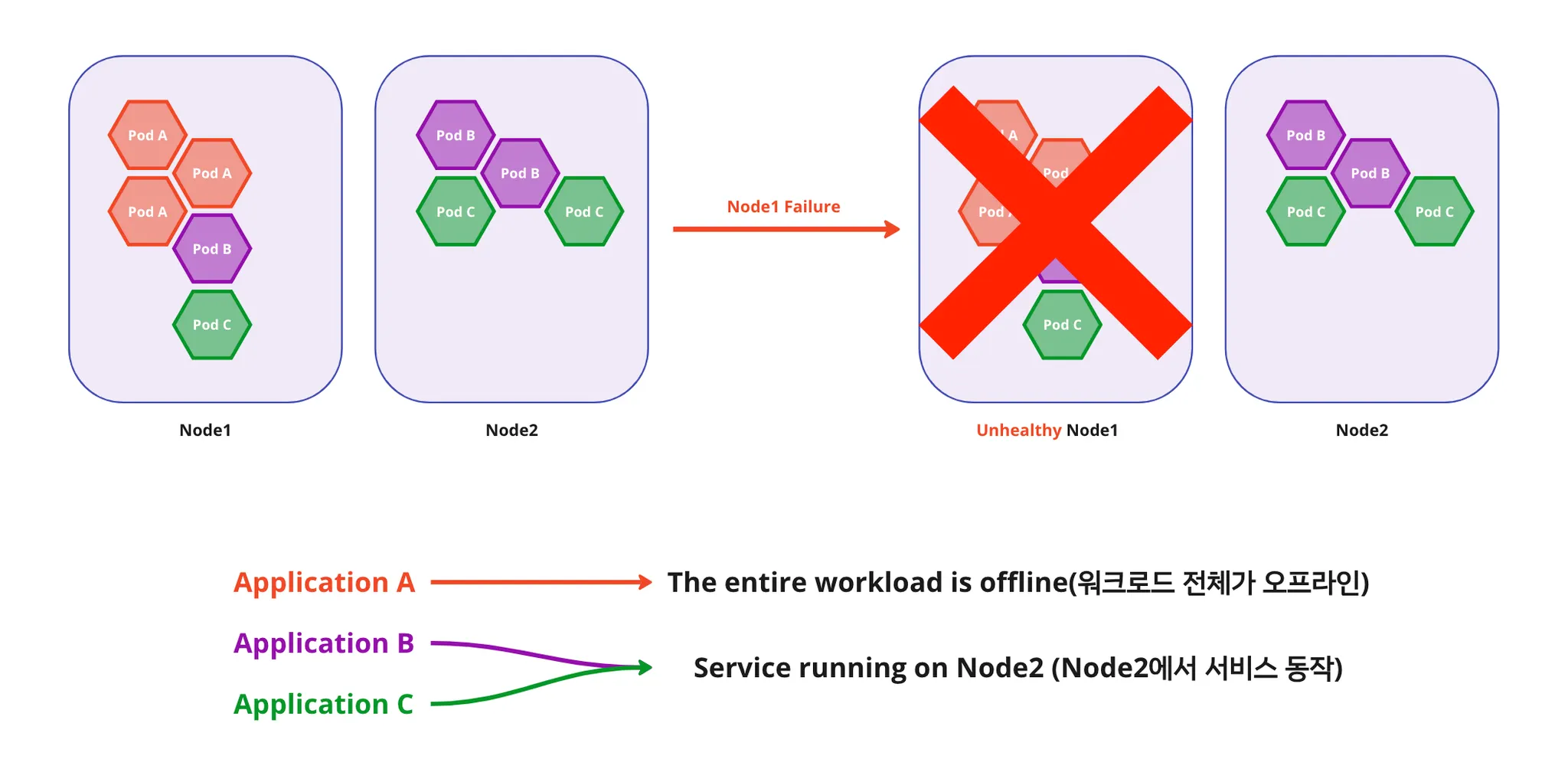
이 때문에 Pod의 replica를 여러 워커 노드에 적절하게 분산하여 스케줄하는 것은 안정적인 서비스 제공에 필수적인 요소입니다.
기존에도 쿠버네티스에는 유사한 문제를 해결하기 위해 Affinity, AntiAffinity 를 제공하고 있습니다.
그러나 이 기능은 Pod를 원하는 노드에 배치하는데 있어서 일부적인 해결일 뿐, Pod를 적절하게 분산시켜서 스케줄링해준다고는 말하기 어렵습니다.
이 포스팅에서는 Pod를 워커 노드에 적절히 분산하기 위한 설정인 topologySpreadConstraints에 대하여 설명하고, 실제로 어떻게 스케줄링 되는지 살펴보겠습니다.
topologySpreadConstraints(토폴로지 분배 제약 조건)
topologySpreadConstraints 를 설정하면 노드(Node), 지역(region), 존(zone) 및 기타 사용자 정의 토폴로지를 기반으로 쿠버네티스 클러스터에 걸쳐 파드가 분배되는 방식을 제어할 수 있습니다.
이를 설정함으로써 고가용성뿐만 아니라 효율적인 리소스 활용의 목적을 이루는 데에도 도움을 줄 수 있습니다.
topologySpreadConstraints는 클러스터 레벨에서 기본값으로 설정할 수도 있고(EKS는 불가능), 개별 애플리케이션마다 각각의 topologySpreadConstraints를 설정하는 것도 가능합니다.
하나 또는 여러개의 topologySpreadConstraint 를 정의할 수 있으며, kube-scheduler는 이 조건들을 함께 고려하여 클러스터의 어떤 노드에 새로운 파드를 배치할지 결정합니다.
topologySpreadConstraints 필드 설명
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# -- Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
YAML
복사
쿠버네티스 Pod API를 살펴보면 spec.topologySpreadConstraints 필드가 있으며, 하위 필드들은 다음과 같이 사용됩니다.
(https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.26/#topologyspreadconstraint-v1-core)
•
maxSkew
◦
maxSkew 값은 파드가 균등하지 않게 분산될 수 있는 정도를 의미합니다.
말이 조금 헷갈리는데 쉽게 말하면, 노드 간에 스케줄링된 Pod의 갯수 차이 허용치입니다.
예를 들어 이 값이 1이면, 노드 간에 Pod 갯수 차이가 1개까지 발생하는 것은 허용하는 것이죠.
이 필드는 필수이며, 0 보다 큰 값을 사용해야 합니다.
◦
maxSkew가 구체적으로 동작하는 방식은 whenUnsatisfiable 의 값에 따라 달라집니다.
◦
whenUnsatisfiable: DoNotSchedule
▪
이 경우, maxSkew는 대상 토폴로지에서 일치하는 파드 수와 전역 최솟값(global minimum, 적절한 도메인 내에서 일치하는 파드의 최소 수)사이의 최대 허용 차이 값을 뜻합니다.
▪
예를 들어, 3개의 존에 각각 2, 2, 1개의 일치하는 파드가 있다고 가정하면 전역 최솟값 은 1로 설정됩니다.
전역 최솟값과의 차이는 1, 1, 0 으로, maxSkew 가 1 이상이면 문제없겠네요.
◦
whenUnsatisfiable: ScheduleAnyway
▪
이 경우, kube-scheduler는 차이(skew)를 줄이는 데 도움이 되는 토폴로지에 더 높은 우선 순위를 부여합니다.
•
topologyKey
◦
노드 레이블의 키(key) 값입니다. 이 키와 동일한 값을 가진 레이블이 있는 노드는 동일한 토폴로지에 있는 것으로 간주합니다.
◦
토폴로지의 각 인스턴스(즉, <키, 값> 쌍)를 도메인이라고 합니다.
•
whenUnsatisfiable
◦
topologySpreadConstraint을 만족하지 않을 경우 파드를 처리하는 방법을 정의합니다.
◦
DoNotSchedule
▪
(기본값) 스케줄러에 스케줄링을 하지 않도록 지시합니다.
◦
ScheduleAnyway
▪
차이(skew)를 최소화하는 노드에 높은 우선 순위를 부여하면서, 스케줄링을 계속하도록 지시합니다.
•
labelSelector
◦
토폴로지 내에서 일치하는 파드를 찾는 데 사용되는 셀렉터입니다.
◦
이 레이블 셀렉터와 일치하는 파드의 수를 계산하여 해당 토폴로지 도메인에 속할 파드의 수를 결정합니다.
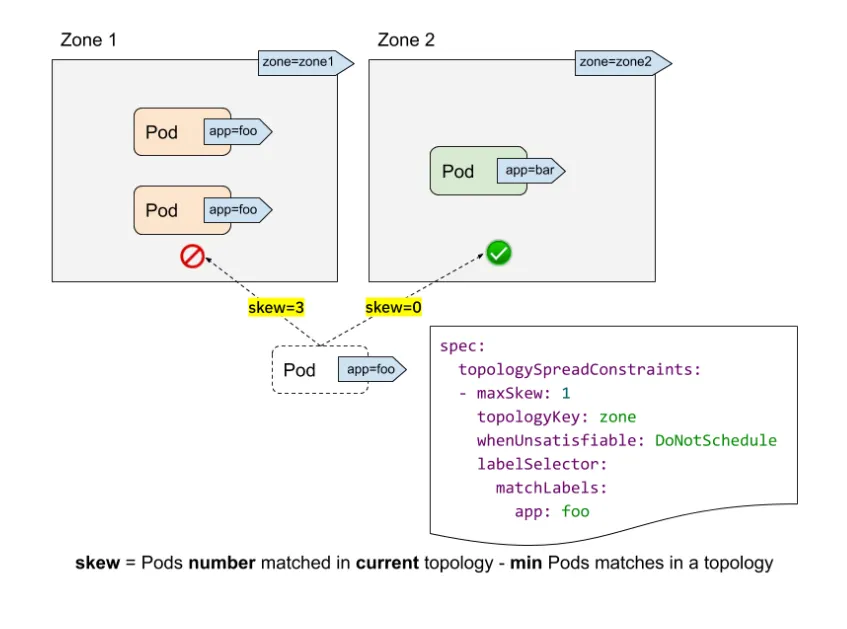
위 그림을 참고로 maxSkew 가 어떻게 영향을 주는지 살펴보겠습니다.
app: foo Pod에 대해 maxSkew 값은 1로 설정되어있습니다.
whenUnsatisfiable: DoNotSchedule로 설정되어있기 때문에, maxSkew 를 만족하지 않으면 Pod를 배치하지 않고 pending 상태로 두게 됩니다.
이때, 스케줄러는 다음과 같이 고려합니다.
•
zone1에는 이미 app: foo 라벨 Pod는 2개가 있고, zone2에는 app: bar 라벨 Pod로 해당되지 않는 Pod가 1개가 있습니다. 이 때 app: foo Pod의 전역 최솟값은 0 입니다.
•
만약 zone1에 추가 app: foo 라벨 Pod를 배치하면 전역 최솟값은 계속 0인데, zone1 에 Pod가 3개가 되어 skew=3이 되고 maxSkew=1을 위반하게 됩니다.
•
zone2에 추가 app:foo 라벨 Pod를 배치하면, zone2에 새로 배치된 Pod 1개로 인해 전역 최솟값이 1이 되고 skew=0이 되어 조건을 만족하여 스케줄링을 진행하게 됩니다.
EKS에서 topologySpreadConstraints 설정
현재 제가 속해있는 프로젝트에서는 EKS를 사용중이며, 여기서 Pod를 분산하는 정책을 설정하여 사용중입니다.
EKS는 기본적으로 multi-AZ로 워커노드가 생성되기 때문에, AZ와 노드 이름을 토폴로지 Key로써 사용할 수 있습니다.
만약 EKS를 사용중이라면 아래 내용을 그대로 사용해도 큰 문제가 없을 것으로 생각합니다.
•
2개의 토폴로지 Key 에 대해 Pod를 분산
◦
topology Key
▪
AWS AZ(Availability Zone)
▪
Node
•
제약 조건에 맞지 않더라도 최대한 분산하며 스케줄링 → ScheduleAnyway
이를 yaml로 작성하면 아래와 같으며 이를 Deployment 등의 워크로드에 추가하여 사용합니다.
## -- EKS topology spread constraint
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
foo: bar
YAML
복사
•
AWS AZ
◦
topologyKey: topology.kubernetes.io/zone (AZ)
◦
maxSkew: 1
◦
whenUnsatisfiable: ScheduleAnyway
•
Node
◦
topologyKey: kubernetes.io/hostname (노드 이름)
◦
maxSkew: 1
◦
whenUnsatisfiable: ScheduleAnyway
EKS에서 테스트
아래 내용은 실제로 위 topologySpreadConstraints 를 적용하여 EKS에 배했을 때 Pod가 어떻게 분산되는지 확인하는 예시입니다.
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-app
namespace: ns-test
spec:
replicas: 4
template:
spec:
containers:
...
...
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: test-app
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: test-app
YAML
복사
위 deployment를 apply하고 kubectl get pods -n ns-test -o wide 를 하면 다음과 같은 Pod의 상태를 볼 수 있으며, 각각의 노드에 Pod가 고르게 분산된 것을 확인할 수 있습니다.
NAME READY STATUS RESTARTS AGE IP NODE
test-app-865587d778-cjnn7 1/1 Running 0 4d22h 100.65.77.9 ip-100-65-76-114.ap-northeast-2.compute.internal
test-app-865587d778-hjh4g 1/1 Running 0 4d22h 100.65.70.73 ip-100-65-69-90.ap-northeast-2.compute.internal
test-app-865587d778-szgxk 1/1 Running 0 4d22h 100.65.69.84 ip-100-65-65-142.ap-northeast-2.compute.internal
test-app-865587d778-th8kc 1/1 Running 0 4d22h 100.65.72.152 ip-100-65-77-224.ap-northeast-2.compute.internal
YAML
복사